Speeding up the sampling phrasetable in moses
The project: ModernMT
I am currently on a 6-week codevelopment workshop in the picturesque town of Trento, Italy. The project with the uninspiring, but aspiring title of “ModernMT” aims to make current machine translation technology easy to use and scale. The targeted simplicity implied some design choices that are supposed to quicken the setup and trial of an SMT (Statistical Machine Translation) system: for example, a quick and simple word aligner used in training, and a suffix array index of the bilingual training corpus instead of a static, pre-computed phrase table as the dictionary.
To boost translation quality, we are furthermore experimenting with domain adaptation. The goal here is to have a good general-purpose translation engine that is excellent (beats Google Translate in translation quality) for specialized domains of text, like patents or software documentation. The ModernMT software identifies the type of input text and assigns domain weights to it, which indicate the input’s similarity to the training domains.
The problem: sampling phrasetable runtime performance
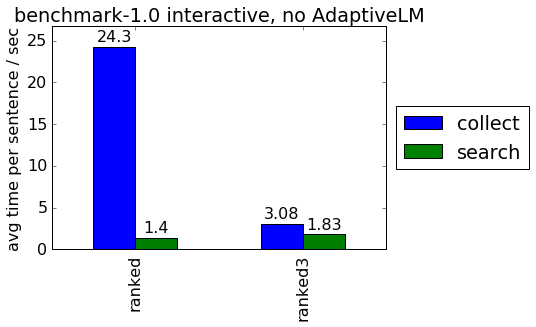
One of my recent tasks was to investigate why the current ModernMT prototype was unbearably slow in an interactive translation scenario, where users feed the SMT system with individual sentences to be translated. On the old prototype, the translation of a single sentence could easily take a minute! Looking at simple timing information collected by the moses decoder, the time spent in the sampling phrasetable (“collecting options” as reported by moses) seems unreasonably high, occasionally taking tens of seconds for only a few words to be translated.
The time used to extract phrase pairs from a constant number of samples should be independent of the words queried - unless the queried source phrase occurs less often than the number of samples, in which case sampling should take less time. On a large training corpus of 1.3 billion words and using 1000 samples, querying a manually selected variety of word types with vastly different frequencies yields this plot:
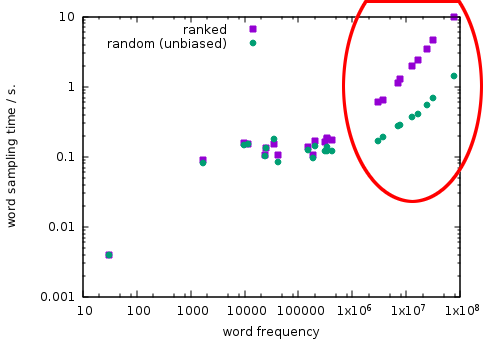
(The two sampling variants ranked and random differ in the strategy used to choose samples if there are more corpus occurrences than samples to be taken).
We can clearly see that the most frequent word tokens like the, ,, a etc. seem to take linear time to query, instead of constant time, and this time becomes unreasonable above about one million occurrences of any word. This design obviously fails to scale up with the corpus size for the given use case, since many word types fall into this “slow” category (circled above) with a large corpus.
To explain the problem, it is now necessary to introduce some used concepts from machine translation. If you are only interested in the performance problem of the actual implementation, you can move on to the section “Implementation details” below.
Sampling phrasetable details
In the project setup, phrase pairs are extracted on-the-fly from the indexed bitext corpus and the word alignment as needed by the decoder for a specific input sentence to be translated. For each possible subspan (source phrase) of the input sentence, the sampling phrasetable looks up the occurrences of that phrase in the source side of the training bitext corpus. Then, phrase pairs are extracted from those word-aligned training occurrences to provide translation options. To avoid unnecessary computation for frequent phrases, a specific constant number of occurrences is considered, drawn randomly (samples parameter).
Domain adapatation: ranked sampling using the sampling phrasetable
Collecting and pooling training data of different machine translation customers can provide much better coverage, leading to the availability of longer phrases and therefore better translations. However, there is a problem: adding large numbers of unrelated translations of the same source words may make translation worse for other customers.
Our current approach to avoid this problem changes the phrase sampling strategy as follows: given the identity of a translation customer and some existing training bitext from that customer, we first sample from that same customer’s
training data, attempting to gather the amount of samples from the relevant training data. Only if that data is too sparse to get enough samples does the algorithm move on to sample from others’ training data. This way, the sampling phrasetable has a built-in preference for the correct, relevant translations.
Implementation details: the performance problem
Having explained the goal of the algorithm, we can move on to investigate the actual implementation. There is one index of the entire training corpus. So how to determine which customer’s sub-corpora to sample from first? Correct – we need to look up the occurrences in the index and then loop over all occurrences to find the ones belonging to the customer. To ensure the correct uniform distribution of the sampling, we need all the occurrences in the customer’s training data, even if there are orders of magnitude more occurrences than we need to sample. Aha! We have found the source of the linear scaling behavior. But how to implement this faster?
Split indexes
The sampling phrasetable needs to sample from individual customers’ training data. So we need a data structure that can answer the question for a constant number of random occurrences of a source phrase for a given customer in time constant with respect to the number of phrase occurrences. This is possible if we build one index per customer: that way, all the occurrences for the given customer will be neatly sorted one after the other in the customer’s index. Then, we only need to draw samples indices from that range, and only have to sample those indices. It does not matter anymore if the corpus has 1,000 or 10,000,000 occurrences of the source phrase, the sampling will take constant time.
I implemented this split index during the co-development workshop in Trento. My implementation is called ranked3 (as opposed to the original ranked algorithm, which already had an experimental version 2). Here are the results in terms of the same plot as above. Note how sampling time in the relevant part of the plot is now independent of the word frequency:
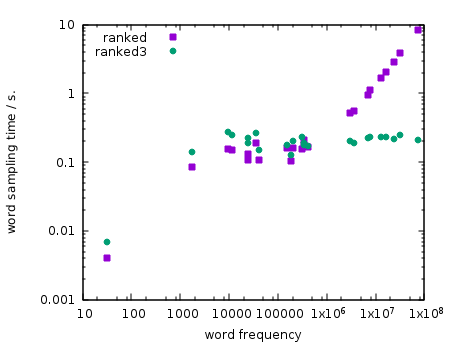
My implementation improves the scenario where users interactively request translation of individual sentences. In this scenario, we cannot cache the phrase pairs (this is because the actual sampling uses context information to intelligently continue sampling using other customer’s training data with similar text, so we couldn’t, for example, use one cache for each customer). On average, sampling is 8 times faster and final translation times are now 5 times faster: